CRM Analytics Data Preparation and Governance – Best Practices and FAQ
Benefits of Analytics Governance
Defining the right balance of flexibility and control means you will realise the benefits of both self-service and governance:
- Providing the right data to the right audience in a secure, governed operational model.
- Building the foundation for every data-driven decision.
- Establishing trust and confidence to drive business value.
- Contributing to the stability of the platform and reducing the proliferation of duplicate data and content with governed workflows.
- Ability to scale your analytics solutions to new use cases and business groups.
General Best Practices
- Data governance – ensuring you’re not duplicating data, optimizing the use of recipe limits, and separation between LOBs, using naming standards in your recipes so your pipelines can be troubleshooted and field names can be interpreted within datasets.
- Data orchestration between recipe schedules and data syncs – starting with daily refreshes on initial go live, then increase to 2X a day, 4X a day, etc.
- Security (flatten node, multivalue type recipes) – enrich datasets for row level security using role hierarchy, account hierarchy. See below in document.
- Snapshotting/incremental changes of data to optimize for recipe speed.
- Run sequential recipes faster with staged data. Reduce processing time when your data strategy involves multiple recipes by using staged data instead of datasets. An initial recipe outputs results as staged data, and subsequent recipes can use the staged data in input nodes. For example, rather than merge account and opportunity data in each region-specific forecasting recipe, merge just one time, output the results as staged data, and use this data in the other recipes. See here.
- Implications of filtering in a recipe vs on data sync or on the dashboard
- Naming datasets
- Avoid renaming datasets with the same label or API name
- When you have a dataset being used in dashboards, and you want to add new fields to it – what is the most efficient way of doing that? This is recommended best practice when testing changes or optimisation of recipes and you don’t want to impact the production dashboard or dataset:
- Save recipe as new
- Make changes then
- Merge back
- How to organize datasets into recipes (Its hard to find which dataset exists in what recipe)
- Converting Dataflows to Recipes? Practical Approach to convert dataflows to recipes.
- Implications of using Direct data in a recipe vs Data Sync?
- Improve recipe performance (reference):
- Extract only the data required
- Minimise the number of joins
- Minimise the number of transformations
- Reduce the number of multi-value columns
- Use a compute expression transformation to aggregate multiple criteria
- Don’t use compute relative for aggregation
- Don’t use filter nodes for conditional logic
- Consider adding a filter at the beginning of your recipe, cause you want to reduce the number of rows where you’re performing calculations
- The impact of Multi-row formulas (compute relatives)
- Multi row formula is the equivalent of Compute relative node which creates groups within your data (partition) and then performs calculation per row, per group
- Computation against a default value vs computation against a null value
- Specify a default value in your core org (it becomes quick and easy)
- Simplify editing large recipes (reference):
- Organize a graph with the cleanup button
- Speed up tasks with keyboard shortcuts
- Change your perspective with zoom
- Streamline and Improve Data Sync (reference):
- Update data using incremental sync
- Use connections to group objects for scheduling
- Reduce the number of fields being synced
- Don’t refresh your data more than you need to
Data Integration Troubleshooting
Use these tips to resolve problems with data integration issues in CRM Analytics (reference):
- Why am I receiving recipe errors? These suggestions can help resolve recipe errors in CRM Analytics:
- Locating Unknown Errors – When a recipe fails, but the error isn’t identified, break the recipe into smaller recipes to pinpoint where the error occurs
- Triggered Object Data Sync – If the recipe triggered an object data sync, check whether the data sync failed and, if it did, review the errors.
- Geolocation Fields –
- Remove unused geolocation fields in data sync
- Specify a Precision metadata override to avoid numeric overflows and other unexpected behaviors.
- Numerical Overflows – If you get a warning that some rows have failed, it could be due to numerical overflows. To resolve a numeric overflow error:
- Remove the longitude or latitude fields from the data source, data sync, dataflow, or recipe if they’re not functionally required.
- Adjust the numeric field’s precision and scale to accommodate the numeric value.
- Make sure that the field values are within the defined maximum and minimum values, including decimal places.
- Why are my data sync and recipe runs getting canceled?
- Tightly scheduled recipe or data sync jobs can result in canceled data sync and recipe runs because too many runs are queued. You can usually avoid this situation by extending the time between a recipe’s or data sync’s scheduled runs.
- Sync timing Matters-while pulling data from Salesforce, bulk request is issued by CRMA, so scheduling your sync when not many bulk jobs in your org are running is important.
- Sync frequency Matters-when you set up a schedule for data connection, you can choose to refresh the cached data in time intervals as short as 15 min up to once a month. However, make sure you understand the limitations as it might not be super realistic to keep a 15 min schedule.
- Have I exceeded my dataset row limit, and what can I do about it?
- All orgs have a dataset row limit. When you exceed this limit or create a recipe that can exceed this limit, you must reduce the number of dataset rows used or increase your limit.
- Why is my recipe or data sync job running out of time or being killed?
- A recipe or data sync job can fail because the integration user can’t authenticate.
- Why was a recipe unscheduled?
- When a user is deactivated, the recipes in which they made the most recent modification are unscheduled to prevent unnecessary runs.
- Why am I receiving a syntax error in the formula node?
- You can perform several types of transformations on fields in Data Prep. However, some field API names are unavailable for these transformations.
- Why is my scheduled recipe not running as expected?
- When recipes are chained together using event-based scheduling, unscheduling or manually running an upstream recipe or connection can result in unexpected outcomes.
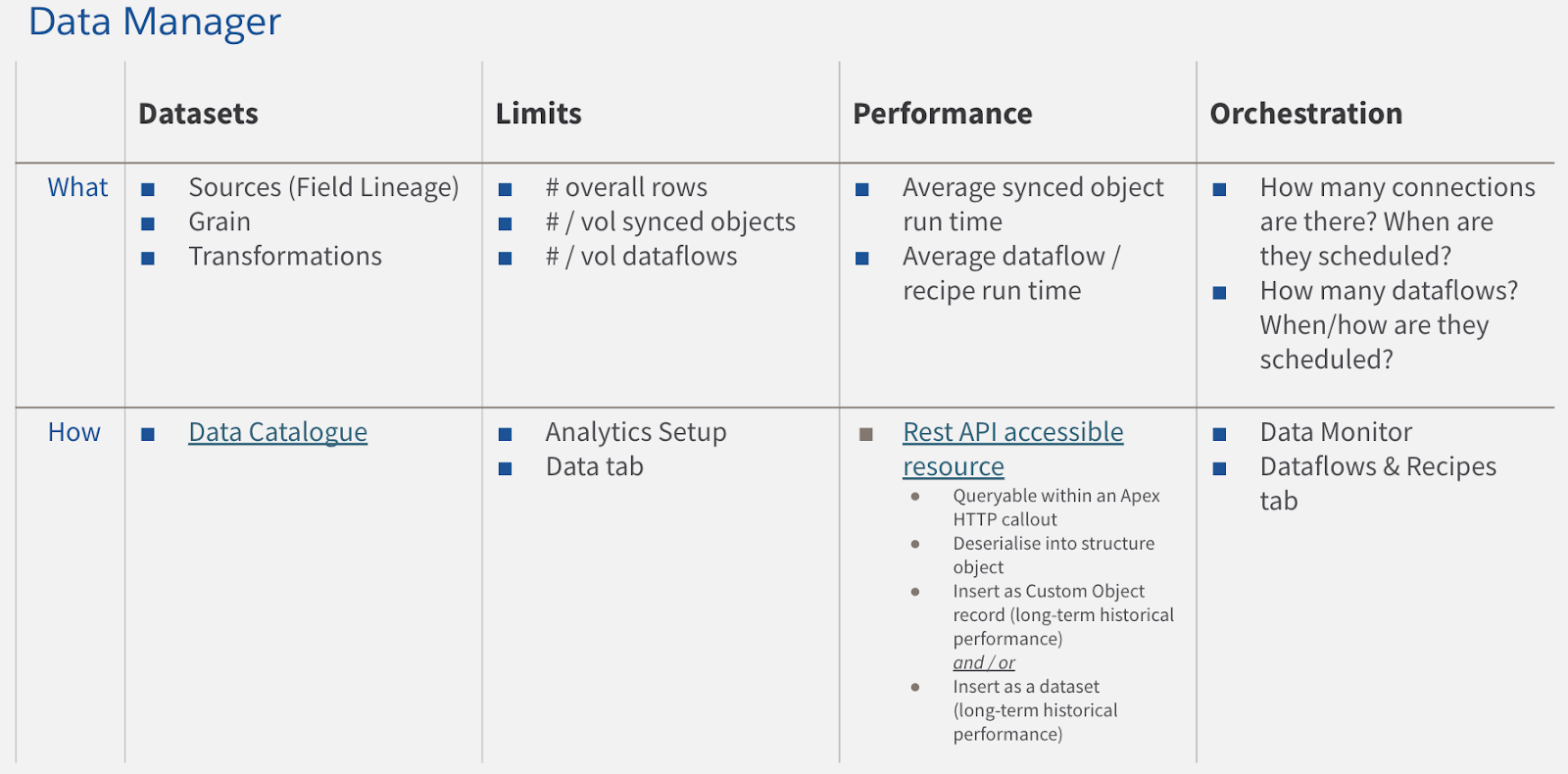
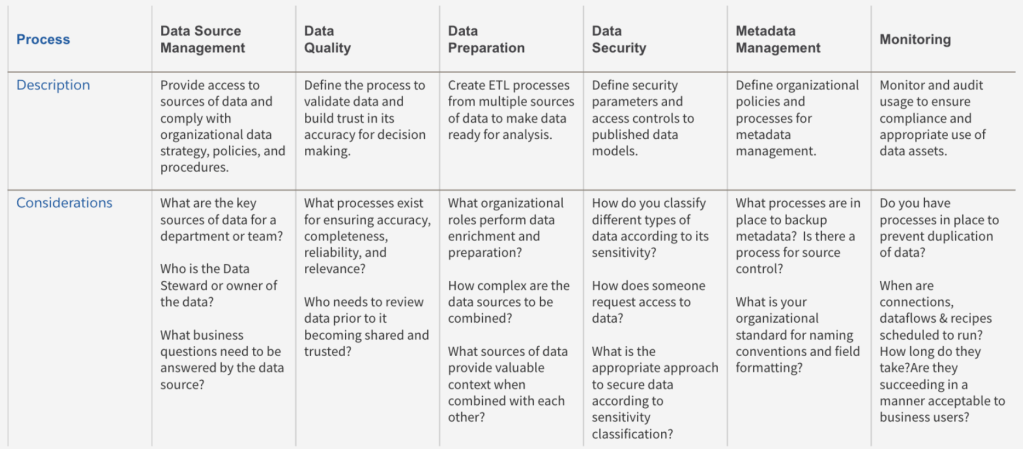
Components of Data Governance
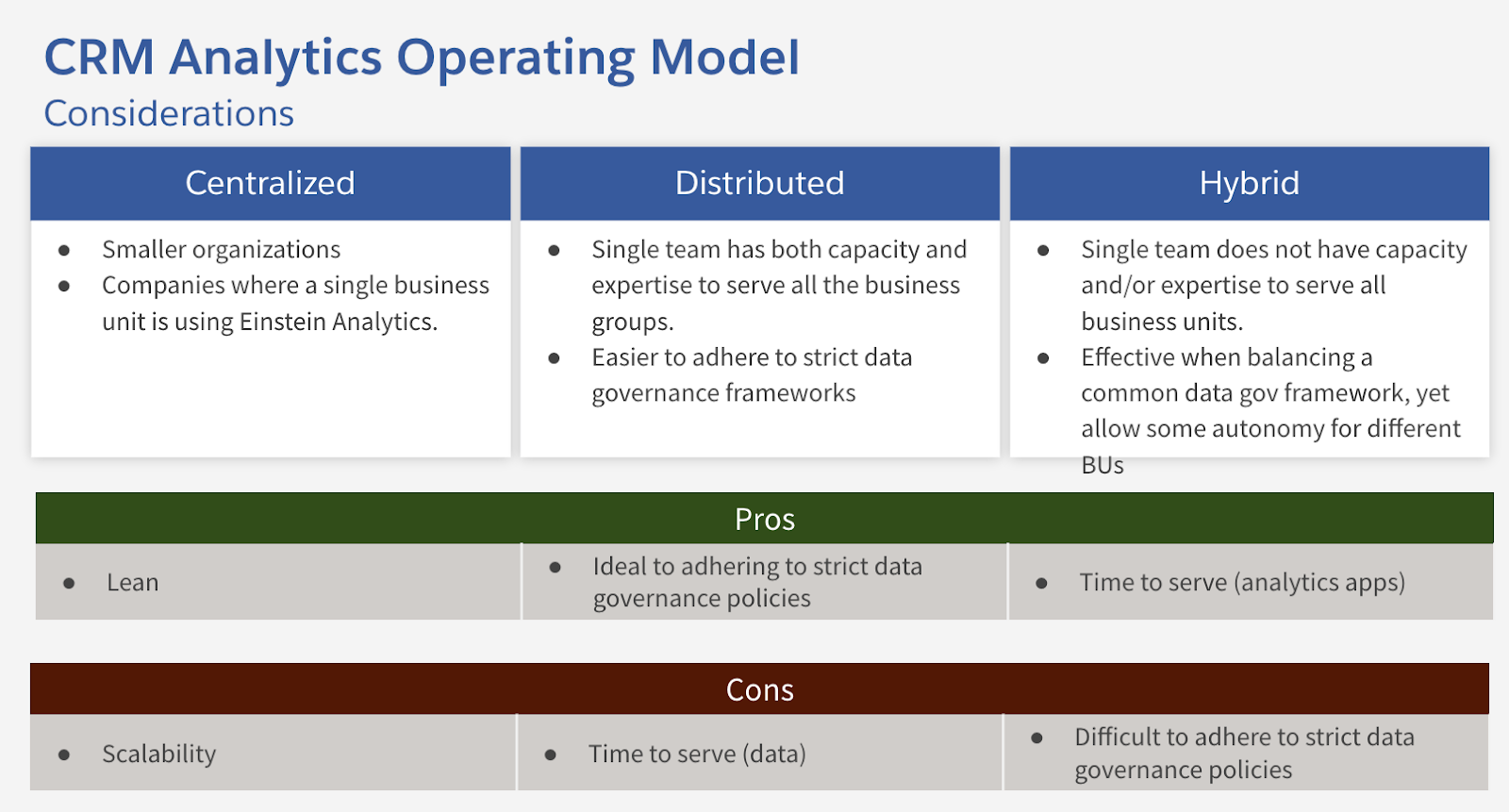
Common CRM Analytics Operating Models
- Centralised
- Creation & Maintenance of data sets governed centrally
- Creation & Maintenance of dashboards governed centrally
- Distributed
- Creation & Maintenance of data sets governed centrally
- Creation & Maintenance of dashboards governed within business units
- Hybrid
- Creation & Maintenance of data sets governed by CoE
- Creation & Maintenance of dashboards governed within business & CoE